Hello Ruby community,
Today we have some good news to announce: We no longer need Redis to run RubyGems.org and we are removing the Nginx SPOF (single point of failure). We have a brand new download stats system in place and we have shut down our Redis instances.
Is Redis bad?
Not at all, if used correctly! A lot of companies use Redis and there are many valid use cases for it. One of the main use cases for Redis is to use it as a queue for background jobs. We use PostgreSQL and DelayedJob for our background jobs instead, so we don’t need Redis for that. Our problems came from the way we were using it and how much data we were storing. We were storing all the data in a permanent, never expiring fashion with quite a bit of storage and memory growth. The main problem we encountered with Redis was the memory required to load the data into a running instance. This was resource intensive and time intensive. If an instance would go down for any reason it would take many minutes to become usable again as it re-loaded everything into memory. We had some Redis failures that took us about 45 minutes to bring it back up. This is not usually a problem when you don’t have a lot of data in Redis (like the background job case).
Our previous stats architecture
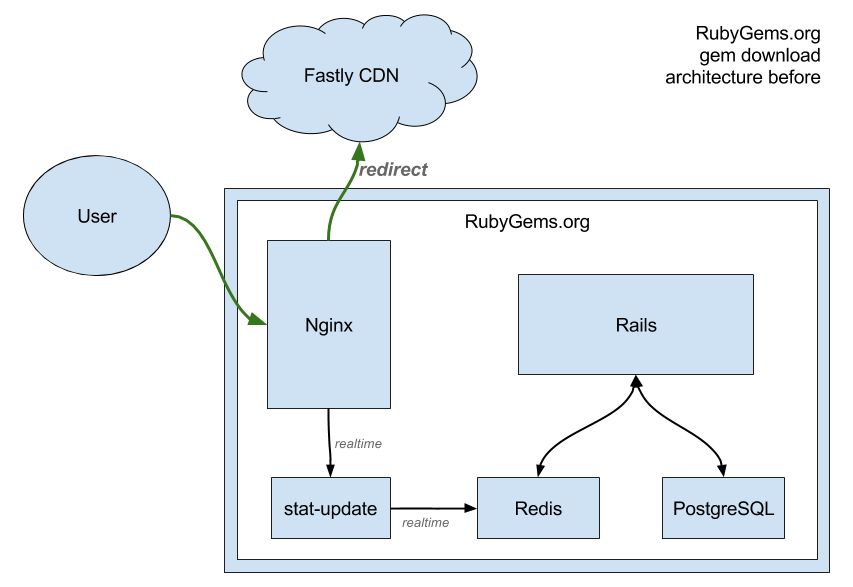
We mainly were using Redis for the gem download counts. The architecture for many years was this:
- Every time a gem was downloaded the request would first pass through our Nginx load balancers.
- Nginx would send a secondary http request to an internal service with the gem information before redirecting the user to our gem CDN.
- This internal service was a small C backend that would parse the request, and increment counters in Redis.
- Those counters from Redis were shown on the various RubyGems.org pages and API responses.
As you can imagine, RubyGems.org receives a lot of download requests. We wanted to serve downloads directly from our CDN but we needed the requests to hit Nginx first to track the downloads. Also, if any part of this architecture was down we would permanently lose download counts.
What are we using now
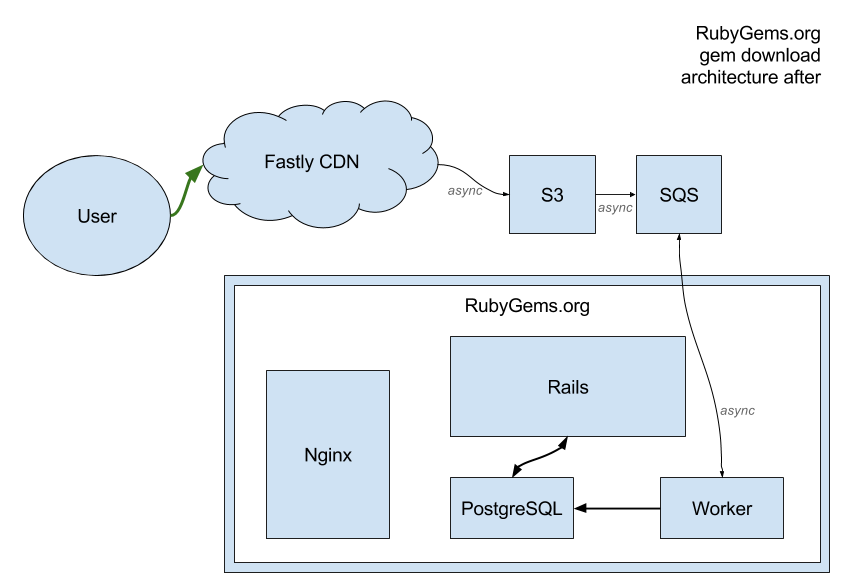
We can now serve all gem downloads directly from Fastly, our CDN provider. Here’s what our new architecture looks like:
- Gems download requests hit Fastly, where the gems may already be cached geographically close to the user.
- Fastly generates a log file every five minutes, and pushes that log file to S3.
- S3 pushes a SQS notification message to a queue.
- The RubyGems.org Rails app consumes those SQS messages and schedules a background job to process each new S3 file.
- DelayedJob works the background job and updates the counters in PostgreSQL.
- The Rails app can now use the counters directly from the PostgreSQL database.
Drawbacks of the new architecture
- Counters are only updated every five minutes. However this is a small price to pay and allows us to do more caching.
Wins on the new architecture
- We can serve .gem downloads directly from CDN at edge locations.
- The number of permanent data stores goes down from 2 to 1, which is a huge win for the resiliency of our service.
- Nginx is no longer required for gem downloads, removing a SPOF.
- Our stack became simpler.
- Smaller downtimes windows.
- Easier local development setup.
- We can pause the background processing or even recount download counts altogether if needed.
Future plans
At the time this was written we are still serving gems via Nginx and a redirect to Fastly. This will be changed in the near future as we complete the full transition to Fastly. Expect another blog post explaining this transition too.
Links
- https://github.com/rubygems/rubygems-infrastructure/issues/35
- https://github.com/rubygems/rubygems.org/issues/1208
- https://github.com/rubygems/rubygems.org/issues/1089
- https://github.com/rubygems/rubygems.org/pull/1176
Special thanks to:
Aaron Suggs, David Radcliffe, Arthur Neves for working hard on this project.